Understanding user support systems in open source
September 27, 2018
As a project matures, one of the biggest demands on a software maintainer’s time is user support: not just bug reports or feature requests, but also “How do I?”-type questions. What starts as an occasional question slowly grows to a support queue, and time spent on the project might go from mostly proactive (coding) to mostly reactive (support) work.
If this were a company, you’d hire a support team; in an open source project, people who are motivated to participate as developers will find themselves doing a different job entirely: a shift that’s challenging to the notion that open source is powered by intrinsic motivations. We can’t have it both ways: either people contribute because they get to do what they like, or we need to find other ways to distribute or manage the support burden.
Fortunately, there are options. While core developers may be reluctant to spend all their time on support, they might be extrinsically motivated to do so (i.e. getting paid for it). Additionally, there are other actors in the ecosystem who are intrinsically motivated to provide support, such as power users who are eager to demonstrate their knowledge in public.
I did some research to understand: How do popular open source projects manage high support volumes? What are the different types of support systems, and how should we evaluate them?
Defining user support
Before we dive in, what does “user support” mean? What type of requests does the typical open source project have to handle?
User support falls into three buckets:
- Bug reports: Something isn’t working
- Feature requests: I want something that doesn’t currently exist
- Questions: “How do I…?”
While the first two are often handled on a project’s issue tracker, I’m particularly interested in the third, which is usually routed to other channels.
Within the definition of support, there are arguably two use cases: those who need help for their own situation (i.e. users) and those who need help contributing back to the project (i.e. contributors). I’d consider both to be a form of user support, but I’ve primarily looked at the former here, as the latter gets us into a whole other philosophical bucket of fish. (Yes, that’s a metaphor and I’m sticking to it.)
Methodology and caveats
Because I’m interested in how popular projects handle user requests, I defined “popular” in terms of issue volume, rather than stars.
I used BigQuery’s GitHub data set to pull the top projects by most issues opened in the last year (8/29/17-8/29/18). [1] Of these, I removed noisy data, like junk repositories, mirrors, and personal projects, to end up with a “top 100” list. Then I went through each project to analyze their support systems. You can find the data and caveats here.
The list isn’t perfect; we’re just looking at issue volume, which doesn’t account for the number of people opening those issues. Some projects probably have fewer people opening a ton of issues, vs. many people opening many issues. I removed extreme examples of the former when I saw them (ex. one bot, or a few people, opening all the issues), but I didn’t get want to get too deeply into subjective judgments (how many people is “a few”?).
A few high-level trends
At what point does issue volume even become a problem for projects? I only did a deep dive into the top 100 projects, but I was curious about this question, so I skimmed down and sampled every 100 projects for the top 2,000 projects.
- The lowest bound for the top 100 was roughly ~30 issues opened per week.
- Support systems (templates, other channels) still seemed common down to projects with ~8-20 issues opened per week.
- Without gathering a ton of manual data, I can’t say when those practices stop being common, but sampling on the lower end of the range (1-2 issues opened per week) definitely looked more hands-off.
So, I’d guess that projects getting more than one issue a day are probably starting to think about scaling up their support needs.
In case you’re wondering which types of projects have high support volume, I noticed a few standouts: gaming, Microsoft-related projects, Vue-related projects, and cryptocurrency. These did not, by any means, make up the majority of projects I looked at; they’re merely a few recurring types that I found remarkable.
I also checked my assumption that it was better to use issue volume instead of star count. On my top 100 list, I found no significant correlation between stars and issues opened in the past year, with a Pearson coefficient of 0.22. Some projects have high support burdens and low star counts; others have high star counts and low support burdens. For analyzing support needs, instead of using stars, it’s better to look at issue volume.
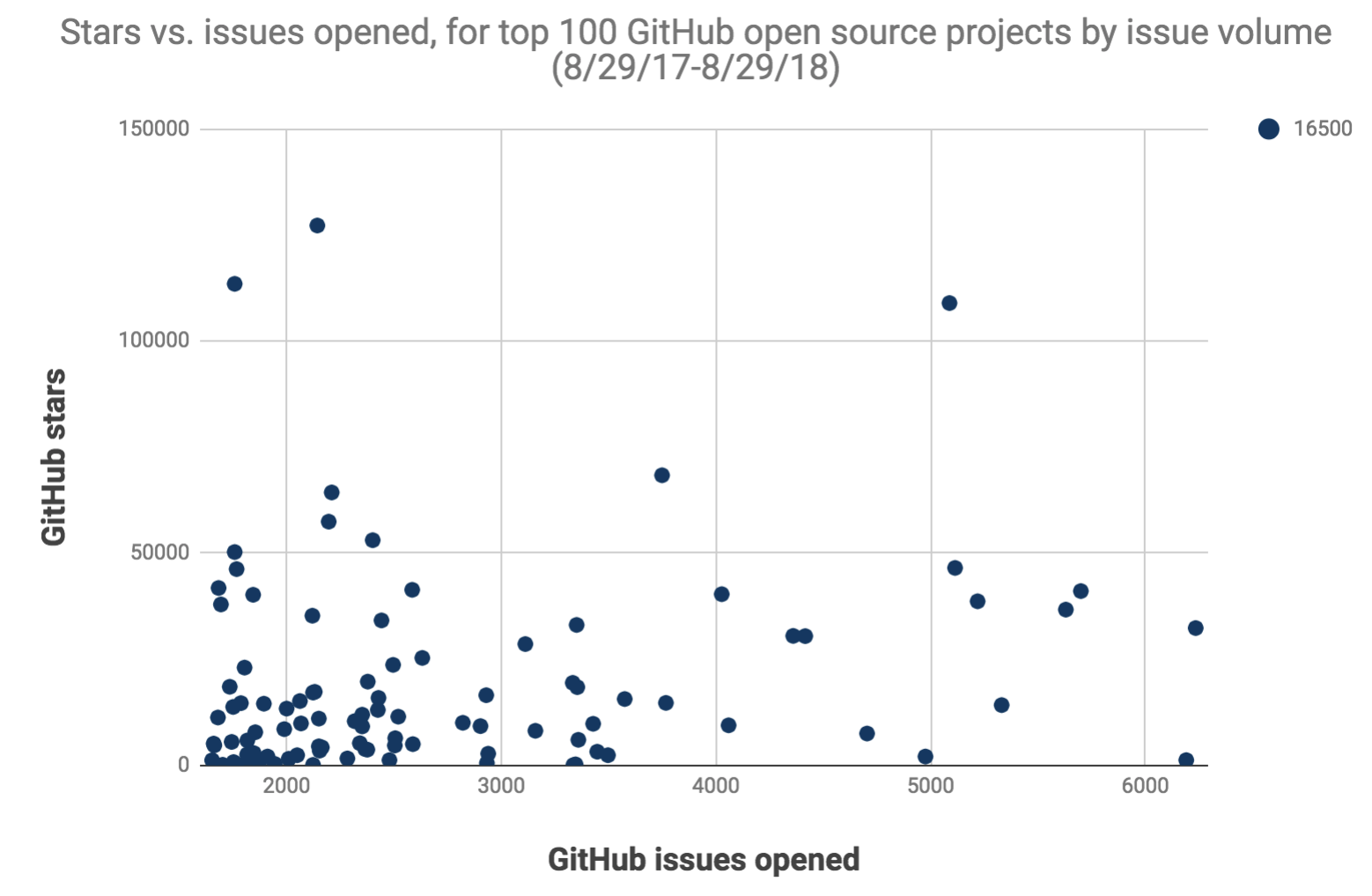 GitHub stars vs. issues opened, for top 100 open source projects by issue volume (8/29/17-8/29/18)
GitHub stars vs. issues opened, for top 100 open source projects by issue volume (8/29/17-8/29/18)
Again: these are “issues opened”, which is a crude proxy of support volume. I did check a few low-star outliers to see if something different was going on, but didn’t notice any weird behavior.
Okay, on to the fun stuff! I’ll summarize my findings in terms of common support patterns, with data to back up each section.
The support page
Not every project has a dedicated support page or README section, but they should, as documentation can help obviate the need for support.
 Support section from CockroachDB’s README
Support section from CockroachDB’s README
Support pages divert noisy traffic away from the issue tracker. They include helpful docs (including FAQs) and links to official support channels, and are usually labeled something like: Support, Troubleshooting, Getting help, etc.
Some projects made it difficult to find support. I wondered whether this might be intentional, where projects (understandably) don’t want to create the expectation that they “offer” support, instead encouraging users to solve problems themselves. However, I think it’s better to call it out, if only to say “We don’t have official support”. Even if core developers don’t want to actively monitor support, they can create or point to channels for users to find and help each other: whether that’s Stack Overflow, IRC, or a mailing list.
A few projects framed support as a form of contribution, encouraging people to ask and answer questions. Calling it “Community” instead of “Support” was confusing to me at first, but I realized it’s meant to attract users with answers - not just those with questions - which is useful for powering a user-to-user support system. For example, React Native suggests on its “How to Contribute” page:
Browse Stack Overflow and answer questions. This will help you get familiarized with common pitfalls or misunderstandings, which can be useful when contributing updates to the documentation.
The issue tracker
Projects tend to use issue trackers for bugs and feature requests, but rarely for questions. For consistency’s sake, I only looked at projects that used GitHub as their primary issue tracker.
Templates
Nearly all (93%) of the projects I looked at used issue templates, and 38% of projects used GitHub’s multiple template UI. Most projects with multiple templates identified three types of issues: bug reports, feature requests, and questions. The «questions» template usually directs users to somewhere else besides the issue tracker. I like Symfony’s use of emoji here:
 Symfony’s new issue templates
Symfony’s new issue templates
Why do issue templates matter? If documentation is the first line of defense, adding gentle friction is the second line to reducing support volume. From rg3/youtube-dl’s README (emphasis mine):
Before we had the issue template, despite our extensive bug reporting instructions, about 80% of the issue reports we got were useless…youtube-dl is an open-source project manned by too few volunteers, so we’d rather spend time fixing bugs where we are certain none of those simple problems apply, and where we can be reasonably confident to be able to reproduce the issue without asking the reporter repeatedly.
As an alternative to issue templates, projects in the Vue ecosystem, like Ant and Nuxt, used “new issue helpers”, which is essentially a contact form.
Issue triage
Some projects used bots as a “first responder” on GitHub issues. For example, Ansible’s @ansibot was involved in 86% of the issues opened in the date range I looked at. Bots respond to issues, add labels, and @-mention relevant people. [2]
I also noticed that developers with more commits didn’t necessarily correlate to their involvement on issues. This disparity points to two distinct “maintainer” roles: issue management and core development. These roles often overlap, but they serve different functions.
To use Ansible as an example again, here’s a sample of their top committers vs. number of issues that involved them. @mattclay has nearly twice as many commits as @sivel, but @sivel was involved in nearly 10x more issues:
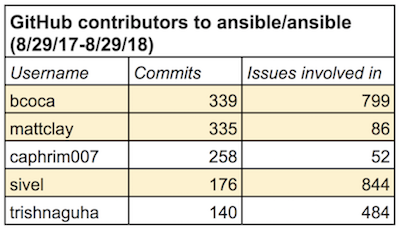 Sample of contributors to Ansible
Sample of contributors to Ansible
On Bootstrap, @Johann-S is involved on quite a few issues, despite having relatively fewer commits:
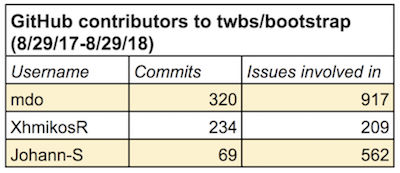 Sample of contributors to Bootstrap
Sample of contributors to Bootstrap
11% of projects used only GitHub issues to manage support, meaning that they didn’t name any other official support channels. (Only two were in the top 50 projects, but I don’t know that this is necessarily correlated to issue volume.) For example, fastlane seems to manage all its support on GitHub, with virtually all questions closed out (see “questions” tag and these issues also). [3]
I’m not sure why some projects do it this way. I’d speculate there might be a few advantages: users are more likely to get an “official” (i.e. correct) answer from a maintainer [4], and all discussions are organized in one place.
Beyond the issue tracker
89% of the projects I looked at used something besides GitHub issues to manage their support needs, listing an average of two support channels other than GitHub issues.
 Godot has 9 (!) support channels, among other community namespaces
Godot has 9 (!) support channels, among other community namespaces
Synchronous support channels
Among synchronous channels, IRC and Gitter were most popular, used by 22% and 20% of projects, respectively. Slack came close (16% of projects), followed by Discord (8%). After that, I saw a long tail of chat products, including Rocket.Chat, Matrix, Telegram, Spectrum, Mattermost, and Riot.
Synchronous channels are rarely used without an asynchronous counterpart, but rather offered as a starting point: a place to route requests or get a quick response. I liked this phrasing from the Julia project:
Slack is also a good place to start if you think you need help but aren’t quite sure what you should be asking or where to ask it.
Asynchronous support channels
The most popular asynchronous channels are dedicated forums (41% of projects), Stack Overflow (38%), and mailing lists (18%), which is consistent with Raza et al’s study of maintenance support. I was surprised to learn that Facebook groups were about as popular as reddit for support (5% and 4%, respectively). A few brave souls (3%) listed their email addresses.
While it might seem redundant to use multiple asynchronous channels, the style of conversation varied between them, an observation also noted by Zagalsky et al in their study of R. Because Stack Overflow is driven by a reputation system, answerers are incentivized to solve the problem themselves and get credit for it. By contrast, on a mailing list and (usually) on forums, users have longer back-and-forths with each other, asking clarifying questions and engaging in dialogue.
I dug through forums and mailing lists to try to understand the makeup of people interacting on these channels, but unlike GitHub data, it was difficult to gather or analyze this information quantitatively, so this mostly amounted to me flailing around in a sea of pseudonymity and getting frustrated.
On Stack Overflow, I looked at a sample of projects (n=10, out of 38 total projects that officially support SO) and their “top” answerers.
For some of the projects I looked at, such as Rust and Bootstrap, one or two people are responsible for the vast majority of answered questions on Stack Overflow. This is consistent with previous research: Zagalsky et al noted that for the R project, “Less than 0.25% of users in both [Stack Overflow and mailing lists] contribute 50% of the answers”, and Lakhani and von Hippel observed that for Apache, “Approximately 50% of the answers on the system were provided by the 100 most prolific providers (2% of all providers).”
Although responses are generally concentrated among a small group of answerers, I’m not sure why some projects have only a couple top people, whereas others had a flatter spread (like angular-cli and pandas). This would be a good area for further research.
I also cross-referenced “top answerers” with their GitHub activity. Overall, I found that while a few answerers were core developers on the project, these were a minority of cases. Most answerers I looked at weren’t involved with the GitHub repository at all, or had opened or interacted with a couple issues or PRs.
Who are these people, then? Zagalsky et al suggest that:
When we looked at the professions of these contributors, we found that many of them are professors, book authors, or both. This implies that their goals include to learn and impart knowledge….Another group of prolific contributors are package maintainers who are likely experts in R and their corresponding packages, and perhaps see these channels as mechanisms to provide support to their users. These assertions should be confirmed in future work.
While I didn’t successfully find biographical information for all answerers, these observations are consistent with my limited results.
The total volume of questions, and percentage of unanswered questions, fluctuates wildly: from <10% unanswered on Rust (note: their top answerer, Shepmaster, is part of Rust’s core team), to >40% on material-ui and angular-cli. Abdalkareem et al suggest in “What Do Developers Use the Crowd For?” that the timeliness and usefulness of Stack Overflow replies will vary depending on the topic.
I’m not sure that “unanswered” is a great metric for questions anyway, because not answering a question can be a useful signal that it’s spammy, duplicative, or otherwise uninteresting to the public. Lakhani and von Hippel also note in their study of Apache mailing lists that 40% of unanswered respondents in their sample received a private reply, suggesting that an “unanswered” question is not necessarily ignored.
Paid support tiers
Finally, 12% of the project I looked at offered a paid support tier, including Woocommerce, Vuetify (via Tidelift), Salt, Symfony, and Yoast.
I didn’t include projects that may not have a direct paid support tier, but company-paid employees (e.g. Microsoft, Google, or Red Hat) who maintain the project, so the overall portion of projects that pay engineers to do support is certainly higher. This is consistent with my earlier hypothesis that not all maintenance tasks are intrinsically motivated.
The paid approach is either complementary to, or incompatible with, a community support system, depending how you look at it. Paid support didn’t tend to replace the community support option. However, doubling down on paid support further increases a project’s dependency on a small group of contributors.
Conclusions and (maybe) useful models
In summary, here’s some of the behavior I observed among the top 100 projects:
- No correlation between star count and issue volume. The latter provides a more dynamic view of project popularity
- Documentation and issue templates (especially multiple templates) provide a first and second line of defense against support
- Most projects use ~2 other channels besides GitHub issues to manage support. Most popular are forums (41%), Stack Overflow (38%), IRC (22%), Gitter (20%), and mailing lists (18%)
- High support volumes are either offloaded onto the community, and/or something that developers get paid to do (12% have paid support tiers, but the total is much higher when accounting for employees who are paid to work on a project)
- We need to expand our definition of “maintainer”: issue management, user support, and writing code are distinct roles. A developer’s commit count doesn’t necessarily correlate to their involvement on issues, and Stack Overflow’s top answerers are often not involved with the project’s codebase
I’d like to expand on these last two points by describing a few models: firstly, the relationship between user-to-user vs. maintainer-to-user support systems, and secondly, the relationship between different maintainer types.
Growth models for user support systems
Scaling support isn’t just an open source problem: it’s a software problem. It’s widely believed that software is successful because it scales costlessly, meaning that more people consuming it doesn’t impose a cost back to the producers. But unlike many digital goods (like a book, or a song), software requires ongoing upkeep and maintenance.
Part of this cost is a function of time, not consumption. Code will rot, regardless of how many people use it. However, user support is a marginal cost associated with software. As more people consume a software project, some percentage of those people will need help using it.
As Google employee DeWitt Clinton put it (emphasis mine):
If you have a billion users, and a mere 0.1% of them have an issue that requires support on a given day (an average of one support issue per person every three years), and each issue takes 10 minutes on average for a human to personally resolve, then you’d spend 19 person-years handling support issues every day. If each support person works an eight-hour shift each day then you’d need 20,833 support people on permanent staff just to keep up. That, folks, is internet scale.
Software companies with massive user adoption are familiar with this problem. It’s especially important to resolve when customers don’t pay for software directly. Google, for example, relies on public forums instead of direct contact forms, which looks a lot like the open source support systems we’ve seen above.
To reduce the marginal cost of support, there are, broadly, two paths available. Either producers offload the cost onto consumers (decentralized approach, e.g. community support systems), or they get paid to work on it (centralized approach, e.g. paid support tier or company-paid employees).
A community support system has its advantages. Asking and answering questions in public helps evangelize the project and improve documentation, which can positively impact user growth. Most importantly, it reduces support cost to maintainers. From the tensorflow/models README:
TensorFlow developers respond to issues. We want to focus on work that benefits the whole community, e.g., fixing bugs and adding features. Support only helps individuals.
On the other hand, it’s impossible to bring this cost down to zero. As support volume grows, maintainer-to-user support should generally decline over time, but it will never be fully eliminated:
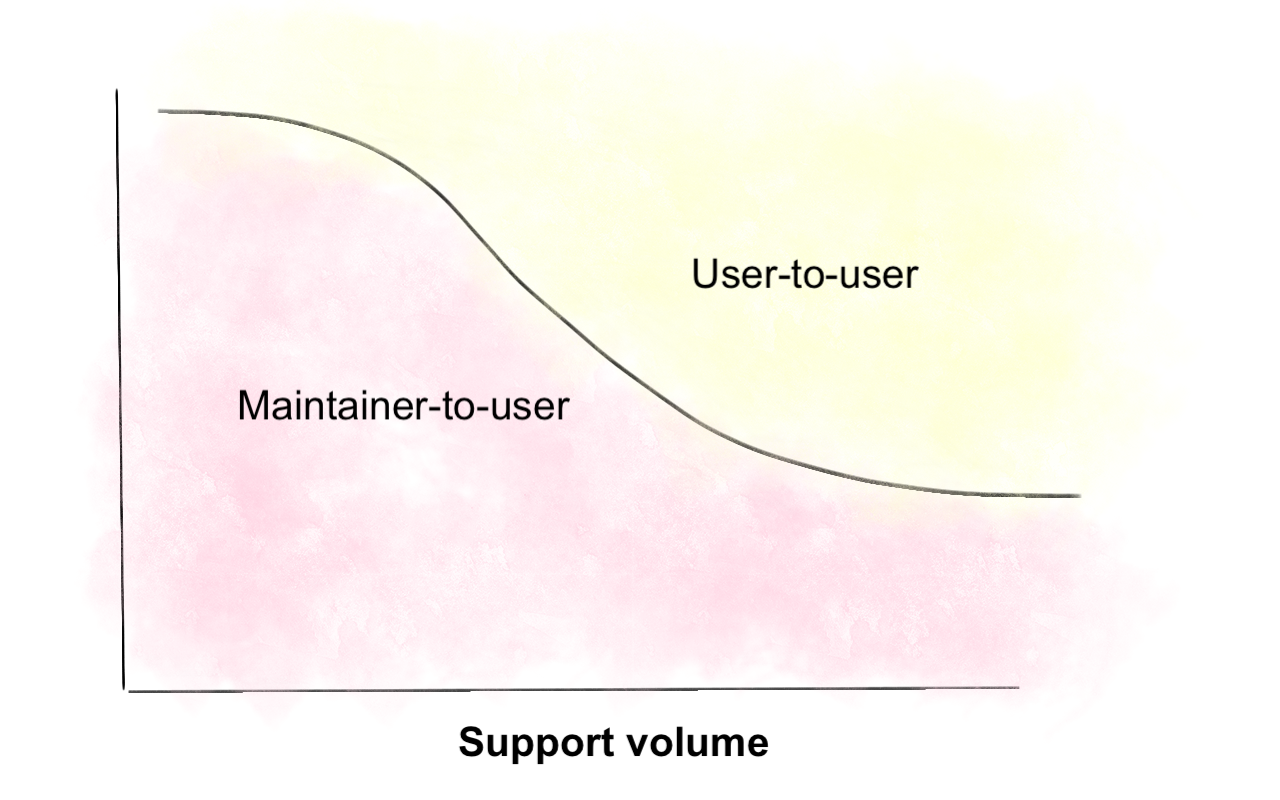
Why is this the case? If we break down different types of user support, they have different growth models.
Questions can be mostly managed among users, but Q&A forums can still be inaccurate or out-of-date. Bugs don’t necessarily need to be handled by core developers, but they still require someone with enough context to assess whether the behavior is expected or not. Feature requests follow an odd trajectory, where I think they become more reliant on maintainers over time. As more people contribute to a project, it’s imperative that someone (or some people) curate those feature requests, holding the vision together.

Reflecting upon the models above, it seems that the motivations of users and maintainers are inversely correlated. When a project is just starting out, a maintainer is motivated to answer questions and review bug reports, because they want people to use it. Over time, their interest declines, but a user’s motivation goes up, because they have a different set of rewards: they want an answer to their question, reputational benefits of demonstrating knowledge, or feel like part of the community.
For a given project, I’d hypothesize that the optimal balance between decentralized vs. centralized support systems can be expressed as the current ratio of user-to-maintainer motivation.
Expanding the definition of a maintainer
Finally, I’d like to expand upon the conclusion that we use an overly narrow definition of “maintainer”. Maintainers aren’t just people with commit access, nor the top committers to a repository. I identified at least three distinct maintainer roles, just in this area of research: core developers, issue triagers, and user support.
Because we don’t talk about these as separate roles, we forget this is a thing, and instead expect that core developers do all the work. This mismatch of expectations can lead to the frustration and burnout that’s often expressed on open source projects.
Officially recognizing these roles is about more than accolades: it empowers everyone to focus on what they do best, thus aligning incentives to continue contributing to the project. A code maintainer shouldn’t have to answer questions all day, and a support maintainer shouldn’t have to commit code, if that’s not what they each want to do. Yet a project needs all three roles (among others!) to thrive.
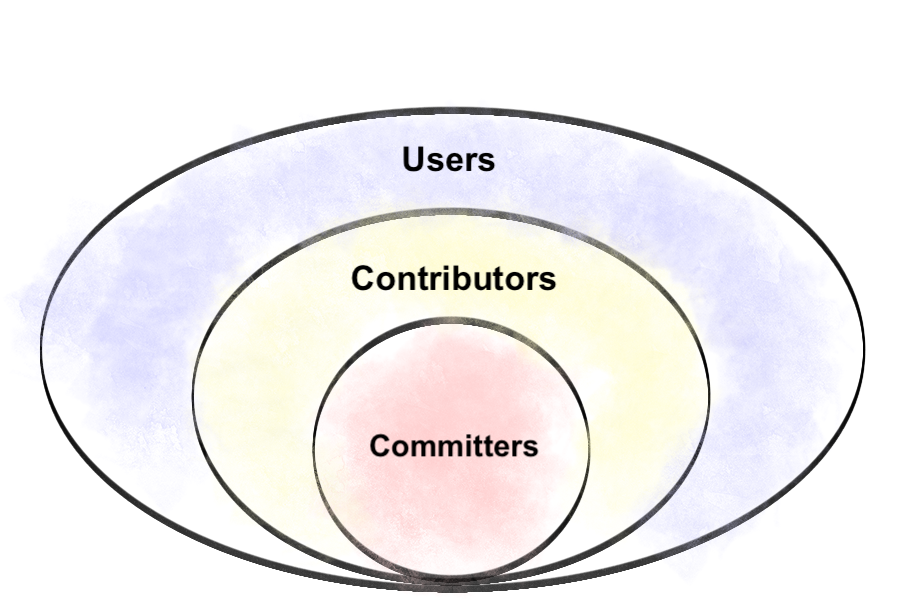
Currently, the most popular method of conceptualizing open source production model is the “onion” model:
I find this model limiting. Instead, I’ve been thinking about a hub-and-spokes model, which, in my view, more accurately represents the full ecosystem of an open source project:
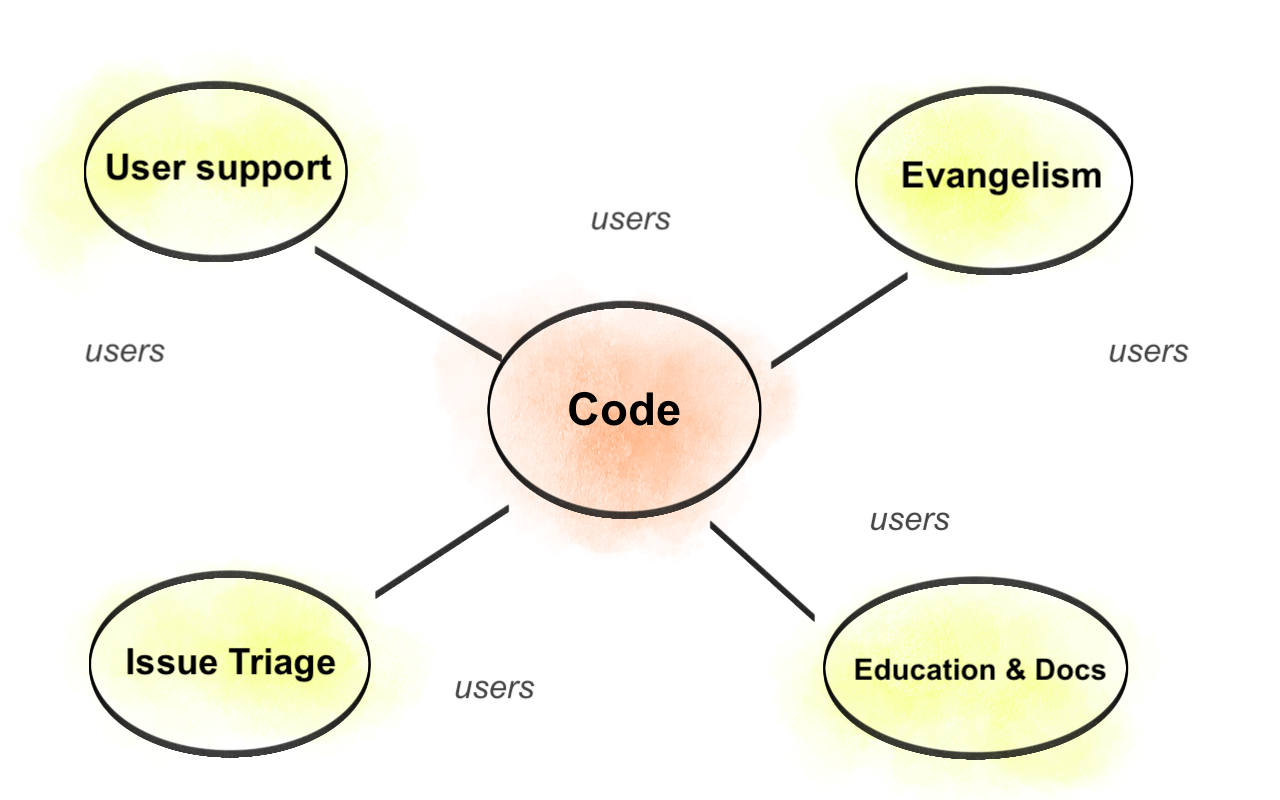
These nodes are illustrative and by no means an exhaustive list. Code is the central “node” of this model, however, because it is the final product that everyone is ultimately trying to evangelize and improve.
Within each node, there’s a natural hierarchy: a few main contributors who act as “maintainers” of their domain, and a wider group of casual contributors. While they might interact with other nodes, each node is its own community.
Users float around as a sort of “electron cloud”, interacting with different nodes based on their specific needs and interests, but not confined to any one place. Most importantly, a user who, say, answers all the questions on Stack Overflow, is considered a maintainer (not a user) in this model.
The “onion” model, by prioritizing commit access, implicitly equates an open source project to its codebase, but a project is much more than its GitHub namespace. Like a coral reef, there’s an entire ecosystem quietly blooming across other channels. It’s up to code maintainers how much they acknowledge or interact with those channels, but user support is one good place to start.
Suggestions for further research
I barely scratched the surface on user support systems: there’s a gold mine of data waiting to be played with. I’d love to see more research on how support communities form and maintain themselves (particularly Stack Overflow, mailing lists, forums, and synchronous chat). Why do some have only one or two answerers, while others have many? Does the growth of these communities mirror that of the code contributor community? Implicitly, a deeper understanding of support communities would help validate the growth model and hub-and-spokes model presented above.
As always, I love getting additional context, clarifications, and stories around any of the projects and information presented above, and will update this post accordingly.
Notes
-
Thanks to my amazing colleagues at Protocol Labs, Raúl Kripalani and David Choi, for the BigQuery help! ↩
-
Much like email automation, there’s an argument to be made that “work begets more work”. I make no comment on the effectiveness of issue bots, but simply note that they’re prevalent. ↩
-
Thanks to Felix Krause for clarifying how questions are labeled on fastlane, which also reminded me he has an excellent detailed blog post about scaling fastlane’s support as a sole maintainer. ↩
-
Theoretically, GitHub issues could be (and sometimes are!) a user-to-user support channel, but given the structure of GitHub repositories, and the lack of reputational incentives on GitHub versus, say, Stack Overflow, I think the the expectation tends to be that issue trackers get “official” responses from maintainers. ↩